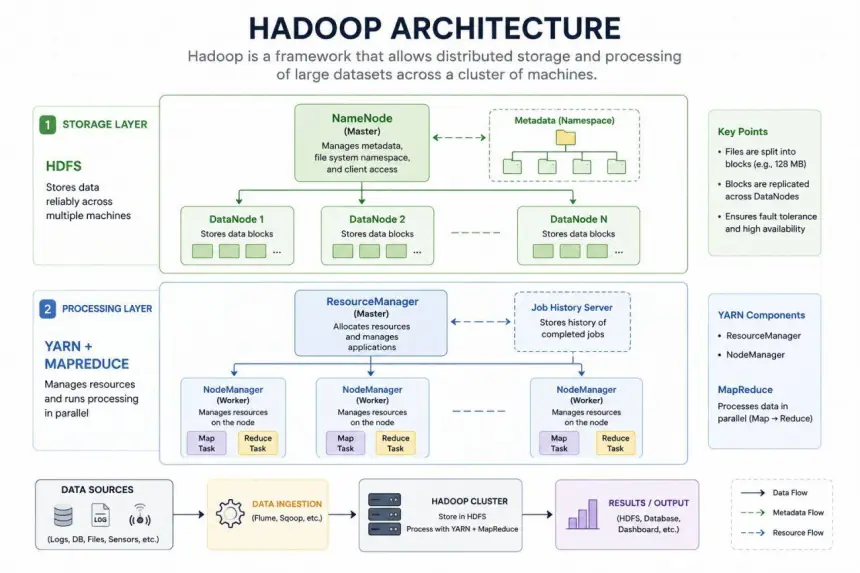
Hadoop architecture: nền tảng xử lý dữ liệu lớn trong kỷ nguyên big data
Khi lượng dữ liệu của doanh nghiệp tăng từ vài gigabyte lên hàng terabyte hoặc petabyte, các hệ quản trị cơ sở dữ liệu truyền thống dần gặp giới hạn về khả năng lưu trữ và xử lý. Hadoop ra đời nhằm giải quyết bài toán đó bằng cách phân tán dữ liệu và tác vụ xử lý trên nhiều máy chủ khác nhau. Bài viết này phân tích chi tiết kiến trúc Hadoop dựa trên sơ đồ trong hình, giúp bạn hiểu cách Hadoop lưu trữ, xử lý và khai thác dữ liệu quy mô lớn.
Hadoop là gì?
Theo sơ đồ, Hadoop là một framework cho phép lưu trữ và xử lý dữ liệu phân tán trên một cụm máy tính (cluster).
Thay vì lưu toàn bộ dữ liệu trên một máy chủ duy nhất, Hadoop chia dữ liệu thành nhiều phần nhỏ và phân phối chúng trên nhiều máy khác nhau. Đồng thời, việc xử lý dữ liệu cũng được thực hiện song song trên nhiều node nhằm tăng hiệu năng và khả năng mở rộng.
Kiến trúc Hadoop trong hình được chia thành hai tầng chính:
- Storage Layer (Tầng lưu trữ)
- Processing Layer (Tầng xử lý)
Bên cạnh đó còn có các thành phần hỗ trợ nhập dữ liệu (Data Ingestion) và xuất kết quả (Results / Output).
Tầng lưu trữ – HDFS
HDFS là gì?
Trong sơ đồ, tầng đầu tiên là HDFS (Hadoop Distributed File System).
Nhiệm vụ chính:
- Lưu trữ dữ liệu trên nhiều máy khác nhau
- Đảm bảo tính sẵn sàng cao
- Đảm bảo khả năng chịu lỗi (Fault Tolerance)
Thay vì lưu một file lớn trên một server, Hadoop sẽ chia file thành nhiều block nhỏ.
Ví dụ:
Một file dung lượng 1GB có thể được chia thành:
- Block 1
- Block 2
- Block 3
- Block 4
- ...
Mỗi block được lưu trên nhiều DataNode khác nhau.
Theo ghi chú trong hình:
- File được chia thành các block (ví dụ 128 MB)
- Các block được nhân bản trên nhiều DataNode
- Đảm bảo High Availability và Fault Tolerance
NameNode – Bộ não của HDFS
Trong sơ đồ, NameNode nằm ở trung tâm của tầng lưu trữ.
Đây là thành phần Master.
Nhiệm vụ:
- Quản lý metadata
- Quản lý namespace của hệ thống file
- Quản lý quyền truy cập
- Theo dõi vị trí các block dữ liệu
Điều quan trọng cần hiểu:
NameNode không lưu dữ liệu thực tế.
Nó chỉ lưu thông tin như:
File A gồm những block nào
Block A nằm ở DataNode nào
Block B nằm ở DataNode nào
Quyền truy cập file ra sao
Có thể hình dung NameNode giống như thủ thư của một thư viện khổng lồ.
Thủ thư không giữ sách trong tay, nhưng biết chính xác cuốn sách nào đang ở vị trí nào.
Metadata Namespace
Trong hình, NameNode kết nối tới Metadata Namespace.
Đây là nơi lưu:
- Cấu trúc thư mục
- Danh sách file
- Thông tin block
- Thông tin replication
Khi người dùng truy cập một file:
- Client hỏi NameNode
- NameNode trả về vị trí block
- Client đọc trực tiếp từ DataNode
Điều này giúp giảm tải cho NameNode.
DataNode – Nơi lưu trữ dữ liệu thực tế
Bên dưới NameNode là:
- DataNode 1
- DataNode 2
- DataNode N
Đây là các Worker Node.
Nhiệm vụ:
- Lưu trữ block dữ liệu
- Phục vụ yêu cầu đọc ghi
- Đồng bộ block với các DataNode khác
Ví dụ:
File có 3 block:
- Block A
- Block B
- Block C
DataNode 1 lưu A
DataNode 2 lưu B
DataNode 3 lưu C
Đồng thời Hadoop có thể tạo thêm các bản sao dự phòng trên các node khác.
Nếu một server bị hỏng:
Hệ thống vẫn hoạt động bình thường nhờ các bản sao còn lại.
Đây chính là cơ chế Fault Tolerance nổi tiếng của Hadoop.
Tầng xử lý – YARN và MapReduce
Sau khi dữ liệu được lưu trữ trong HDFS, Hadoop cần một cơ chế để xử lý dữ liệu.
Trong sơ đồ, tầng thứ hai gồm:
- YARN
- MapReduce
YARN là gì?
YARN (Yet Another Resource Negotiator) là hệ thống quản lý tài nguyên của Hadoop.
Theo sơ đồ:
YARN có nhiệm vụ:
- Quản lý tài nguyên
- Phân phối tài nguyên
- Điều phối các ứng dụng xử lý dữ liệu
Có thể hiểu YARN giống như hệ điều hành của cả cluster.
ResourceManager – Bộ điều phối trung tâm
Trong sơ đồ, ResourceManager là thành phần Master của YARN.
Nhiệm vụ:
- Phân bổ CPU
- Phân bổ RAM
- Quản lý Job
- Theo dõi trạng thái cluster
Khi có một job mới:
- ResourceManager nhận yêu cầu
- Xác định node nào còn tài nguyên
- Giao nhiệm vụ cho các NodeManager
Nhờ đó Hadoop có thể sử dụng tài nguyên hiệu quả trên hàng trăm hoặc hàng nghìn server.
NodeManager – Worker quản lý tài nguyên
Mỗi máy chủ trong cluster sẽ chạy một NodeManager.
Nhiệm vụ:
- Quản lý CPU
- Quản lý RAM
- Theo dõi tiến trình xử lý
- Báo cáo trạng thái về ResourceManager
Trong hình, mỗi NodeManager chịu trách nhiệm thực thi:
- Map Task
- Reduce Task
Job History Server
Đây là thành phần lưu lại lịch sử xử lý.
Nó giúp:
- Theo dõi hiệu năng
- Debug lỗi
- Kiểm tra kết quả job
Đặc biệt hữu ích khi cluster xử lý hàng nghìn tác vụ mỗi ngày.
MapReduce – Trái tim của Hadoop
MapReduce là mô hình xử lý dữ liệu song song.
Trong hình:
Map → Reduce
là quy trình xử lý chính.
Giai đoạn Map
Map có nhiệm vụ:
- Đọc dữ liệu
- Phân tích dữ liệu
- Chia dữ liệu thành các phần nhỏ
Ví dụ:
Đếm số lần xuất hiện của từ trong hàng triệu tài liệu.
Map sẽ đọc từng tài liệu và tạo ra:
Hadoop -> 1
Big -> 1
Data -> 1Giai đoạn Reduce
Reduce nhận kết quả từ Map.
Nhiệm vụ:
- Tổng hợp
- Gom nhóm
- Tính toán kết quả cuối cùng
Ví dụ:
Hadoop -> 50000
Big -> 30000
Data -> 45000Nhờ cách làm này, Hadoop có thể xử lý lượng dữ liệu cực lớn bằng cách tận dụng sức mạnh của nhiều máy chủ cùng lúc.
Quy trình xử lý dữ liệu trong Hadoop
Phần cuối của sơ đồ mô tả luồng dữ liệu hoàn chỉnh.
Bước 1 – Data Sources
Nguồn dữ liệu có thể đến từ:
- Database
- Log files
- CSV
- JSON
- Sensors
- IoT
- Clickstream
- Application Logs
Bước 2 – Data Ingestion
Dữ liệu được đưa vào Hadoop thông qua:
- Apache Flume
- Apache Sqoop
- ETL Pipeline
Nhiệm vụ:
- Thu thập dữ liệu
- Chuyển đổi dữ liệu
- Đưa dữ liệu vào HDFS
Bước 3 – Hadoop Cluster
Dữ liệu được lưu trong HDFS.
MapReduce xử lý dữ liệu.
YARN điều phối tài nguyên.
Toàn bộ cluster hoạt động như một siêu máy tính phân tán.
Bước 4 – Results / Output
Kết quả cuối cùng có thể được xuất ra:
- HDFS
- Database
- Data Warehouse
- Dashboard BI
- Reporting System
Ví dụ:
- Báo cáo doanh thu
- Phân tích hành vi người dùng
- Machine Learning Dataset
- Business Intelligence
Tại sao Hadoop từng thay đổi ngành dữ liệu?
Trước Hadoop:
Muốn xử lý dữ liệu lớn phải mua các máy chủ cực mạnh với chi phí rất cao.
Sau Hadoop:
Có thể ghép hàng trăm máy chủ giá rẻ thành một cluster khổng lồ.
Những ưu điểm nổi bật:
- Mở rộng ngang dễ dàng
- Chi phí thấp
- Chịu lỗi tốt
- Xử lý dữ liệu song song
- Hỗ trợ Big Data quy mô Petabyte
Đây chính là nền tảng cho sự phát triển của Big Data trong hơn một thập kỷ qua.
Kết luận
Kiến trúc Hadoop được xây dựng xoay quanh hai thành phần cốt lõi: HDFS để lưu trữ dữ liệu phân tán và YARN + MapReduce để xử lý dữ liệu song song.
Trong mô hình này, NameNode quản lý metadata, DataNode lưu dữ liệu thực tế, ResourceManager điều phối tài nguyên và NodeManager thực thi các tác vụ MapReduce. Toàn bộ hệ thống phối hợp với nhau để tạo thành một nền tảng xử lý dữ liệu lớn có khả năng mở rộng gần như không giới hạn.
Mặc dù ngày nay nhiều công nghệ mới như Spark, Kafka, Iceberg hay Data Lakehouse đang phát triển mạnh, nhưng những nguyên lý cốt lõi của Hadoop vẫn là nền tảng kiến thức quan trọng đối với bất kỳ kỹ sư dữ liệu, kiến trúc sư hệ thống hoặc chuyên gia Big Data nào.