Giao thức đồng thuận Raft — từ nguyên lý, cấu trúc, vận hành, ưu nhược, đến ứng dụng thực tế
Giao thức đồng thuận Raft — từ nguyên lý, cấu trúc, vận hành, ưu nhược, đến ứng dụng thực tế — dành cho bạn, Randy, với vai trò một kỹ sư phần mềm, để có cái nhìn sâu và đồng thời dễ áp dụng vào các hệ thống phân tán.

1. Tổng quan về Raft
1.1 Khái niệm và mục tiêu
Raft là một thuật toán đồng thuận (consensus) được thiết kế để làm cho việc hiểu và triển khai hệ thống có khả năng chịu lỗi (fault-tolerant) trở nên dễ dàng hơn. Theo trang chính thức:
“Raft is a consensus algorithm that is designed to be easy to understand. It’s equivalent to Paxos in fault-tolerance and performance.” raft.github.io+1
Tức là Raft có khả năng chịu lỗi và hiệu năng tương đương với thuật toán Paxos – thuật toán rất phổ biến trong các hệ thống phân tán – nhưng Raft được thiết kế với mục tiêu đơn giản hơn, rõ ràng hơn, thuận lợi hơn cho người phát triển, người học và triển khai hệ thống thực tế. Stanford University+1
Một cách ngắn gọn: Raft là cách để một nhóm máy chủ (servers) trong một cụm (cluster) đồng ý với một chuỗi các lệnh (log entries) và đảm bảo rằng dù có vài nút (node) bị hỏng (crash) thì toàn bộ hệ thống vẫn đúng và nhất quán (consistency) khi hoạt động. raft.github.io+1
1.2 Vì sao phải có thuật toán đồng thuận?
Trong các hệ thống phân tán – nhất là hệ thống cần độ sẵn sàng cao (high-availability) và nhất quán mạnh (strong consistency) – chúng ta thường muốn có một loạt các máy chủ cùng sao chép lại dữ liệu / trạng thái và phục vụ khách hàng như thể chỉ có một máy chủ duy nhất hoạt động. Đây chính là mô hình máy trạng thái sao chép (replicated state machine). Trang Raft định nghĩa:
“Consensus is a fundamental problem in fault-tolerant distributed systems. Consensus involves multiple servers agreeing on values. … A typical consensus algorithm … a cluster of 5 servers can continue to operate even if 2 servers fail.” raft.github.io+1
Vậy, dong thuận (consensus) cung cấp ba yếu tố quan trọng:
-
Safety (an toàn): không bao giờ cho kết quả sai.
-
Liveness (khả năng tiếp tục hoạt động): hệ thống vẫn hoạt động nếu đa số (majority) các nút còn hoạt động.
-
Consistency (nhất quán): tất cả các nút đồng ý với cùng một giá trị/log.
1.3 Lịch sử và xuất phát
Raft được đưa ra bởi Diego Ongaro và John Ousterhout, trong bài báo mang tên “In Search of an Understandable Consensus Algorithm” (2014) tại hội nghị USENIX ATC. Stanford University+1
Họ xác định rằng: mặc dù Paxos rất mạnh mẽ, nhưng khó học, khó triển khai; Raft ra đời với mục tiêu làm cho thuật toán đồng thuận trở nên “có thể hiểu được” hơn. Stanford University
|
|
|
|
|
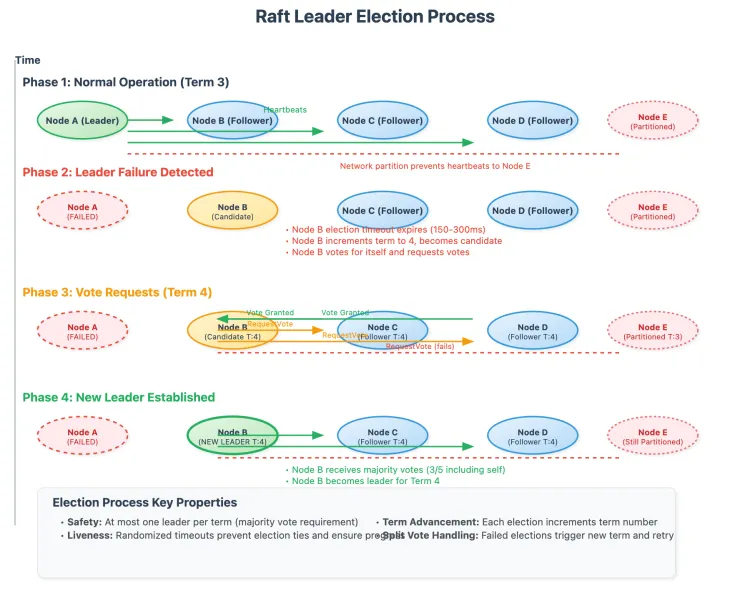
2. Kiến trúc và nguyên lý hoạt động
2.1 Thành phần cơ bản
Trước khi đi sâu, chúng ta cần nắm một số khái niệm và thành phần trong Raft:
-
Máy chủ (server / node): mỗi node chạy Raft và có thể ở trạng thái follower, candidate, hoặc leader.
-
Term (kỳ): mỗi lần bầu lãnh đạo mới bắt đầu một term mới (term number tăng lên). Term dùng để xác định thời gian logic và tránh bỏ phiếu quá hạn. FreeCodeCamp
-
Log (nhật ký các lệnh): mỗi lệnh từ client được ghi vào log leader, sau đó được sao chép (replicate) tới các followers. Các log entry có cấu trúc gồm (term, index, command). Stanford University+1
-
State Machine sao chép (Replicated State Machine – RSM): các node thực thi các lệnh theo cùng thứ tự; nếu log giống nhau thì state máy giống nhau. Stanford University+1
2.2 Trạng thái của một node
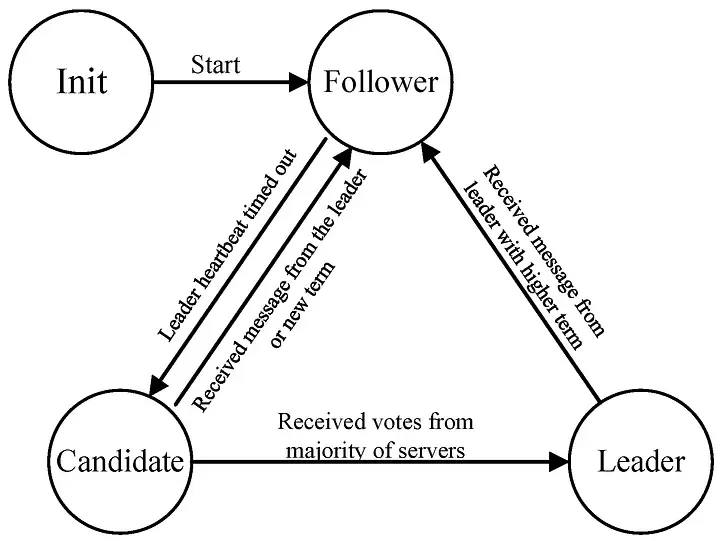
Mỗi node trong Raft có thể ở một trong ba trạng thái:
-
Follower: trạng thái mặc định; lắng nghe các RPC (remote procedure call) từ leader hoặc candidate, không chủ động gửi request.
-
Candidate: khi follower hết thời gian chờ (election timeout) mà không nhận được heartbeat từ leader, nó biến thành candidate, tăng term, tự bỏ phiếu cho mình và gửi RequestVote tới các node khác.
-
Leader: nếu candidate nhận được đa số vote thì trở thành leader. Leader chịu trách nhiệm nhận lệnh từ client, ghi vào log mình, và gửi AppendEntries tới followers để sao chép. Leader cũng periodic gửi “heartbeat” (AppendEntries rỗng) để giữ quyền làm leader. FreeCodeCamp
2.3 Bầu lãnh đạo (Leader Election)
Khi nào thì bầu lãnh đạo? Khi leader hiện tại chết hoặc mất kết nối với đa số hoặc bị partition, hoặc ban đầu cluster khởi động chưa có leader. Cơ chế:
-
Follower có election timeout (ngẫu nhiên trong khoảng, ví dụ 150-300ms) nếu hết thời gian mà không nhận heartbeat, nó chuyển sang candidate. FreeCodeCamp+1
-
Candidate tăng currentTerm, bỏ phiếu cho mình, gửi RequestVote đến mọi node khác.
-
Mỗi node chỉ bỏ phiếu 1 lần mỗi term. Vote được cấp nếu candidate’s log “ít lỗi” hơn hoặc bằng log của voter (chi tiết hơn sẽ nói sau).
-
Nếu candidate nhận được vote từ đa số cluster, trở thành leader. Nếu không ai thắng (split vote), term kết thúc và một term mới bắt đầu.
-
Khi leader gửi heartbeat (AppendEntries) và follower nhận được với term >= currentTerm, follower reset timeout và tiếp tục là follower.
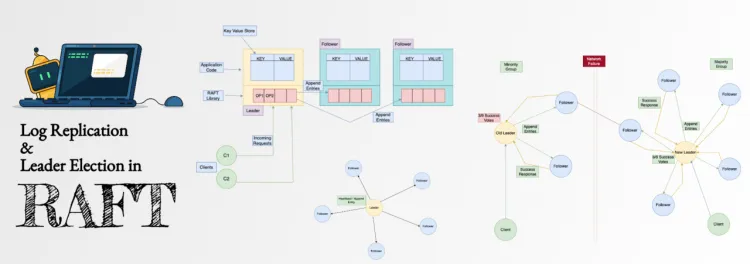
2.4 Ghi và sao chép log (Log Replication)
Sau khi có leader, tiến trình sao chép log đi như sau:
-
Client gửi yêu cầu (command) đến leader.
-
Leader ghi lệnh vào log của mình với thông tin (term, index).
-
Leader gửi AppendEntries RPC tới mỗi follower, bao gồm các log entries mới và thông tin về prevLogIndex, prevLogTerm để followers xác nhận log khớp.
-
Follower nhận AppendEntries: nếu prevLogIndex/Term không khớp với log của follower, follower từ chối (reply false), leader sẽ lùi lại (decrement nextIndex) và gửi lại log từ vị trí phù hợp.
-
Khi follower đồng bộ log thành công, follower gửi ack tới leader. Khi leader nhận được ack từ đa số (bao gồm leader) cho một entry, nó đánh dấu entry đó là committed và gửi thông báo cho các followers để apply entry vào state machine.
-
Tất cả các entry trước entry đó cũng được commit bởi vì log là append-only.
-
Một follower khi biết entry đã được commit sẽ apply entry vào state machine.
Điểm quan trọng: log phải giống nhau về chỉ mục và nội dung giữa các node, và leader phải đảm bảo an toàn trước khi commit. Stanford University+1
2.5 Nguyên tắc an toàn (Safety)
Raft định rõ một số nguyên tắc để đảm bảo hệ thống luôn nhất quán:
-
Election safety: tại mỗi term chỉ có nhiều nhất một leader được bầu.
-
Leader append-only: một leader không được ghi lại log cũ hoặc xóa log, chỉ được thêm vào cuối.
-
Log matching: nếu hai log có cùng entry (term, index), thì mọi entry trước đó cũng phải giống nhau.
-
Leader completeness: nếu một log entry được commit trong term t thì tương lai bất cứ leader nào cũng sẽ chứa log entry đó hoặc các log entry sau đó.
-
State machine safety: nếu một máy đã apply một log entry, thì không một máy nào apply một command khác ở cùng index. Wikipedia+1
Để đảm bảo điều này, trong bầu lãnh đạo mới (candidate) phải có log “ít lỗi” hơn hoặc bằng log của bất kỳ node nào trong đa số. Việc so sánh log dựa vào (lastLogTerm, lastLogIndex): nếu term lớn hơn thì log “mới” hơn; nếu bằng thì index lớn hơn là mới hơn. Wikipedia
2.6 Thay đổi thành viên cụm (Cluster Membership Changes)
Một đặc tính rất quan trọng của Raft là cách thay đổi membership (thêm hoặc bớt node) mà vẫn đảm bảo an toàn. Raft sử dụng cơ chế “joint consensus” (chuyển cấu hình song song) để đảm bảo rằng trong giai đoạn chuyển đổi, các commit yêu cầu đa số trong cả cấu hình cũ và mới. Wikipedia mô tả:
“Given server configuration C_old … and C_new … Log entries are committed to every server in C_old and C_new. … Agreement for elections and log entry commits requires majorities from both C_old and C_new.” Wikipedia
Điều này giúp tránh tình trạng “split‐brain” khi thành viên thay đổi.
2.7 Tóm tắt luồng hoạt động bình thường
-
Khởi động: mọi node là follower với term = 0.
-
Một follower timeout không nhận heartbeat ⇒ trở thành candidate, term++, gửi RequestVote.
-
Nếu ứng viên nhận đa số vote ⇒ trở thành leader, gửi ngay AppendEntries (heartbeat) tới followers để khẳng định quyền.
-
Client gửi command tới leader, leader ghi log, gửi AppendEntries tới followers.
-
Khi leader nhận ack từ đa số ⇒ commit entry, rồi apply vào state machine, trả kết quả cho client.
-
Leader tiếp tục gửi heartbeat thường xuyên; nếu leader chết hoặc mất kết nối ⇒ không gửi heartbeat ⇒ follower timeout ⇒ bắt đầu election mới.
3. Raft và các vấn đề thường gặp trong hệ thống phân tán
3.1 Xử lý lỗi node và phân vùng mạng
-
Leader bị mất: nếu leader chết hoặc mất kết nối, followers sẽ timeout ⇒ election mới được tổ chức ⇒ cluster vẫn tiếp tục hoạt động nếu đa số node còn sống.
-
Follower bị mất: followers chậm hoặc xuống sẽ không ảnh hưởng tới khả năng commit; leader vẫn cần đa số node nhưng không nhất thiết tất cả. Follower khi hồi phục sẽ catch-up log từ leader.
-
Phân vùng mạng (network partition): giả sử cluster có 5 node, chia thành 2 và 3; phần 2 không thấy leader ⇒ election sẽ diễn ra nhưng không thể giành đa số (2 < 3) ⇒ không có leader ⇒ không có tiến trình ghi mới ⇒ consistency được bảo đảm. Phần 3 vẫn có leader và hoạt động. Khi phân vùng kết thúc, follower từ phần 2 sẽ catch-up log.
Các đặc tính trên cho thấy Raft đúng với yêu cầu hệ thống chịu lỗi: hoạt động khi đa số node còn sống và đúng.
3.2 Kinh nghiệm triển khai thực tế
Một số điểm cần lưu ý khi triển khai Raft:
-
Election timeout phải > heartbeat interval và tốt nhất có một bit ngẫu nhiên để tránh nhiều node cùng timeout cùng lúc (giảm split vote).
-
Tối ưu log sao chép: nếu follower rất chậm, leader có thể gửi snapshot thay vì gửi toàn bộ log từ đầu để giảm độ trễ và lưu trữ.
-
Cân bằng tải: vì toàn bộ put/command đi qua leader nên leader có thể trở thành nút cổ chai (bottleneck) nếu khối lượng lớn.
-
Thay đổi membership phải được triển khai cẩn thận: bộ thuật toán song song (joint consensus) có vẻ phức tạp hơn so với phần còn lại của Raft.
-
Snapshot & log compaction: để tránh log tăng vô hạn, cần cơ chế lưu trạng thái (snapshot) và xóa log cũ. Raft có đề cập nhưng các triển khai thực tế thường phải mở rộng.
3.3 So sánh với Paxos
Nhiều bài viết phân tích rằng Raft và Paxos giống nhau về bản chất nhưng khác về cách tiếp cận. Ví dụ:
“Though many distributed consensus algorithms have been proposed, just two dominate production systems: Paxos … and Raft … We find that both Paxos and Raft take a very similar approach … differing only in their approach to leader election.” arXiv
Điều này có nghĩa: nếu bạn đã hiểu Paxos, Raft sẽ không là bước nhảy quá lớn; nhưng đối với người mới hoặc muốn sự rõ ràng, Raft có lợi thế.
4. Ưu điểm & Nhược điểm
4.1 Ưu điểm
-
Dễ hiểu: Raft thiết kế để “hiểu được” – tách thành các phần rõ ràng (leader election, log replication, membership changes) ⇒ thuận lợi cho việc học và triển khai. Stanford University
-
Rõ ràng cấu trúc leader-based: Với một leader duy nhất tại mỗi term, luồng dữ liệu và kiểm soát đơn giản hơn.
-
Triển khai nhiều thư viện: Nhiều ngôn ngữ có thư viện Raft, cộng đồng rộng, giúp dễ bắt đầu.
-
Thay đổi thành viên cụm được hỗ trợ: Cơ chế joint consensus giúp nâng cấp cụm mà vẫn bảo đảm safety.
-
Hiệu năng tương đương Paxos trong nhiều trường hợp thực tế.
4.2 Nhược điểm
-
Leader là nút cổ chai: Mọi ghi (write) đều qua leader ⇒ nếu workload rất cao hoặc phân phối địa lý rộng, có thể bị giới hạn. Wikipedia nêu:
“Leader Bottleneck … Raft uses a single leader model … performance and scalability may be limited.” Wikipedia
-
Không chịu lỗi Byzantine: Raft giả định máy chủ chỉ bị crash hoặc disconnect — không xử lý máy chủ cố tình gian lận hoặc độc hại (Byzantine). Wikipedia
-
Việc thay đổi thành viên khá phức tạp: Mặc dù hỗ trợ, nhưng triển khai chính xác yêu cầu đúng, nếu sai có thể lỗi an toàn.
-
Yêu cầu đồng bộ và cấu hình hợp lý: Election timeout, heartbeat interval, snapshot logic cần tinh chỉnh để tránh split vote hoặc lag.
-
Phần lớn nghiên cứu tập trung vào cluster nhỏ (vài chục node); mở rộng lớn cần cân nhắc thêm tối ưu.
5. Ứng dụng thực tế & khi nào nên dùng Raft
5.1 Ứng dụng
Raft đã được sử dụng rộng rãi trong các hệ thống phân tán sản xuất, ví dụ:
-
etcd (hệ thống key-value phân tán) sử dụng Raft để quản lý metadata và đồng bộ.
-
CockroachDB, TiDB/TiKV sử dụng Raft cho lớp replication. (Theo danh sách trên Wikipedia) Wikipedia+1
-
Hệ thống cấu hình phân tán, coordination service, log replication service.
5.2 Khi nào nên chọn Raft
Bạn – với kinh nghiệm kỹ sư phần mềm và đặc biệt đang quan tâm tới các hệ thống backend, đa domain, đa dịch vụ như bạn Olask đang làm – có thể cân nhắc Raft khi:
-
Cần một hệ thống chịu lỗi (faulttolerant) với đa số node vẫn phục vụ được nếu một vài node hỏng.
-
Cần trạng thái sao chép đồng nhất giữa các node (replicated state machine) như hệ thống kiểm soát cấu hình, metadata, dịch vụ phân tán.
-
Muốn thuật toán rõ ràng, dễ hiểu – thuận lợi cho bảo trì, mở rộng, debug.
-
Chấp nhận mô hình leader-based (tất cả ghi qua leader) và workload ghi không vượt quá khả năng của một node leader hoặc có thể sharding/partition khác để giảm tải.
-
Khi không cần chịu lỗi Byzantine hoặc trường hợp gian lận phức tạp (nếu cần Byzantine thì phải chọn thuật toán khác).
5.3 Khi nào có thể không thích hợp
-
Nếu hệ thống của bạn cần throughput cực lớn, phân tán trên hàng trăm hoặc hàng nghìn node và cần mã hóa tải ghi (write) cao thì mô hình single leader có thể thành giới hạn.
-
Nếu bạn cần chịu lỗi Byzantine (máy chủ có thể bị hack, giả mạo) thì Raft không đáp ứng.
-
Nếu bạn muốn một mô hình peer-to-peer (không leader) hoàn toàn, thì Raft không thực sự thiết kế cho điều đó.
6. Triển khai – Những điểm kỹ thuật cần lưu ý (với góc nhìn kỹ sư)
Vì bạn là kỹ sư phần mềm, việc hiểu cách triển khai Raft – và những “góc kỹ thuật” quan trọng – sẽ rất hữu ích.
6.1 Thời gian khóa (timeouts) và heartbeat
-
Leader phải gửi heartbeat (AppendEntries rỗng) đến followers trong khoảng thời gian nhỏ hơn giá trị election timeout để followers không tự biến thành candidate.
-
Election timeout thường được chọn ngẫu nhiên trong khoảng (ví dụ 150-300ms) để phân tán thời điểm followers chuyển thành candidate và giảm khả năng split vote. FreeCodeCamp
-
Relation: — tức là: thời gian gửi message đến toàn cụm phải rất nhỏ so với timeout, và timeout nhỏ hơn nhiều so với trung bình thời gian giữa các lần lỗi (MTBF) để hệ thống ổn định. Wikipedia
6.2 Cấu trúc dữ liệu log
-
Mỗi log entry: term, command (có thể là một lệnh thay đổi trạng thái), index.
-
Node lưu trữ currentTerm, votedFor (trong term hiện tại máy đã bỏ phiếu cho ai), log (array entries).
-
Khi leader gửi AppendEntries: gồm (term, leaderId, prevLogIndex, prevLogTerm, entries[], leaderCommit).
-
Follower kiểm tra nếu log ở prevLogIndex có term == prevLogTerm; nếu không khớp, trả về false => leader sẽ giảm nextIndex của follower và retry.
-
Khi follower khớp, gửi true và leader cập nhật matchIndex/followers nextIndex.
-
Khi leader thấy matchIndex[i] ≥ N (nhiều node đã có entry index N) và log[N].term == currentTerm, leader commit N (through update commitIndex).
6.3 Snapshot và log compaction
-
Khi log quá lớn, leader và followers có thể mất quá nhiều tài nguyên nếu phải giữ từ đầu. Giải pháp: snapshot state machine tại một điểm, lưu snapshot + thông tin lastIncludedIndex/lastIncludedTerm, sau đó có thể xóa các log entry trước lastIncludedIndex.
-
Leader có thể gửi InstallSnapshot RPC tới follower chậm.
-
Cần coordinate snapshot để không mất consistency.
6.4 Membership changes (thêm/bớt node)
-
Phải chuyển đổi cấu hình (configuration) từ C_old → C_new qua giai đoạn joint (cả hai config cùng active) rồi chuyển sang C_new.
-
Khi ở trạng thái joint, quyền bầu leader và commit log yêu cầu đa số của cả C_old và C_new. Sau khi commit entry cấu hình C_new, cấu hình cũ bỏ đi.
-
Nếu node mới chưa có log hoặc chưa caught‐up thì cần xử lý để không ảnh hưởng quyền đa số.
Việc này hơi phức tạp nên triển khai cần cẩn trọng.
6.5 Xử lý trường hợp lệch log và tái đồng bộ
-
Khi follower quá chậm hoặc vừa khởi động lại, leader cần phải gửi lại log entries hoặc snapshot cho follower đến khi follower caught up.
-
Khi leader mới được bầu, nó phải đảm bảo rằng log của nó chứa tất cả các entries đã commit trước đó (Leader completeness). Nếu không, có thể dẫn đến mất dữ liệu hoặc vi phạm consistency.
-
Vì vậy, điều kiện ứng viên được bầu leader bao gồm: ứng viên phải có log “ít lỗi” hơn hoặc bằng mọi log trong đa số nodes — follower khi bỏ phiếu sẽ từ chối nếu log ứng viên không đủ mới.
6.6 Thông báo tới client & đọc (reads)
-
Ghi (writes) yêu cầu thông qua leader, commit khi đa số đã replicate. Leader có thể trả kết quả cho client sau khi commit.
-
Đọc (reads) có thể được tối ưu: nếu strict consistency, đọc cũng phải thông qua leader hoặc leader phải đảm bảo log đã được commit và update tồn tại trên đa số before trả kết quả. Một số triển khai hỗ trợ “lease reads” hoặc follower reads nhưng cần cẩn trọng để không vi phạm consistency.
-
Nếu bạn xây dựng dịch vụ có các domain multiple mà bạn đang phát triển (như bạn với Laravel + microservices + đa domain), thì nếu có phần lưu trữ/metadata cần đồng bộ mạnh giữa các domain, Raft rất phù hợp.
6.7 Deploy trong môi trường thực tế
-
Số node thường là lẻ (3, 5, 7) để dễ tính đa số.
-
Nên dùng ổ lưu trữ ổn định (stable storage) để lưu currentTerm, votedFor, log entries và snapshot để node có thể khởi động lại mà không mất thông tin.
-
Cần giám sát leader lẫn followers: nếu leader thường xuyên bị bầu lại, điều đó có thể do election timeout quá nhỏ hoặc mạng chậm hoặc lải nhải (heartbeat interval lớn).
-
Cân nhắc phân vùng địa lý: nếu các node ở nhiều vùng địa lý, latency cao sẽ ảnh hưởng broadcastTime và electionTimeout phải lớn hơn.
-
Logging và metrics: theo dõi commit latency, replication lag, thời gian cần để follower bắt kịp, số lần leader thay đổi.
7. Liên quan tới kiến trúc hệ thống của bạn – những lưu ý dành cho Randy
Bạn hiện đang làm nhiều việc liên quan tới backend, microservices, multi-domain, SSO, Docker/Dokku, Redis queue… Có vài điểm mà Raft có thể gắn vào và vài điểm cần lưu ý:
-
Nếu bạn xây dựng một hệ thống quản lý metadata (ví dụ: dịch vụ đăng nhập SSO, cấu hình người dùng, domain module enable/disable) cần đảm bảo nhất quán mạnh giữa nhiều instance – Raft có thể dùng để đồng bộ log cấu hình giữa các node dịch vụ.
-
Khi bạn triển khai đa domain, nhiều dịch vụ, một cụm Raft có thể đảm nhiệm “dịch vụ cấu hình phân tán” (distributed config service) mà tất cả module khác phụ thuộc.
-
Với Docker/Dokku và cluster nhỏ/ vừa (3-5 node) thì mô hình Raft khá phù hợp. Nếu bạn mở rộng hàng chục node phân tán toàn cầu, cần xem xét thêm khả năng sharding hoặc hệ thống đa cụm (multi-cluster).
-
Vì bạn có sử dụng nhiều công nghệ (Laravel, Livewire, React, backend Python AI…): mức độ viết log replication, đồng bộ trạng thái có thể nằm ngoài ngôn ngữ cụ thể — bạn có thể dùng thư viện Raft trong Go, Java hoặc Rust rồi expose via API tới dịch vụ PHP/Laravel.
-
Kết hợp với Docker + Kubernetes (hoặc Dokku) nên đảm bảo nodes Raft có mạng ổn định, latency thấp, ổ lưu trữ persistent để lưu log/chứng nhận.
-
Cần chuẩn bị cho các tình huống cluster bị phân vùng (network partition) hoặc node chậm – vì nếu election timeout quá nhỏ hoặc heartbeat interval quá lớn, cluster có thể hay bầu lại (churn), ảnh hưởng tới performance.
-
Xét tới việc đọc (reads): nếu nhiều module chỉ đọc cấu hình mà ít ghi, bạn có thể cân nhắc bộ cache local trước, nhưng ghi vẫn phải qua leader Raft để đảm bảo consistency.
-
Xem xét snapshot/log-compaction khi log replication tăng nhiều, tránh tràn bộ nhớ hoặc ổ đĩa.
8. Kết luận
Thuật toán Raft – với mục tiêu làm cho việc đồng thuận trong hệ thống phân tán trở nên dễ hiểu và dễ vận hành hơn – là một lựa chọn rất phù hợp trong nhiều hệ thống backend, nhất là khi bạn muốn xây dựng một thành phần chịu lỗi, đồng bộ mạnh và có thể mở rộng tốt. Với kinh nghiệm phát triển đa domain, đa dịch vụ của bạn, Raft có thể là phần cơ bản để xây dựng một lớp infrastructure vững chắc (như service cấu hình, coordination, metadata sync) mà các module khác của bạn phụ thuộc.
Tuy nhiên, như mọi kỹ thuật, ra quyết định dùng Raft cần cân nhắc theo yêu cầu cụ thể về throughput, quy mô cluster, latency mạng, và mô hình lỗi bạn cần chịu đựng. Nếu hệ thống của bạn lớn hơn nhiều hoặc cần chịu lỗi Byzantine, có thể cần công nghệ khác hoặc mở rộng Raft thêm.