Redis hay Kafka: đâu là lựa chọn phù hợp cho hệ thống của bạn?
Redis và Kafka là hai công nghệ xuất hiện rất thường xuyên trong các hệ thống hiện đại. Tuy nhiên, nhiều lập trình viên mới tiếp cận thường nhầm lẫn giữa hai công cụ này vì cả hai đều có khả năng xử lý dữ liệu theo thời gian thực. Thực tế, Redis và Kafka được thiết kế để giải quyết những bài toán hoàn toàn khác nhau. Hiểu đúng bản chất của từng công nghệ sẽ giúp bạn xây dựng hệ thống nhanh hơn, ổn định hơn và dễ mở rộng hơn trong tương lai.
Tại sao Redis và Kafka thường bị đem ra so sánh?
Khi xây dựng các hệ thống lớn, chúng ta thường gặp các yêu cầu như:
- Tăng tốc độ truy xuất dữ liệu
- Giảm tải Database
- Xử lý dữ liệu thời gian thực
- Kết nối các Microservices
- Xử lý hàng triệu sự kiện mỗi ngày
- Xây dựng kiến trúc Event-Driven
Lúc này Redis và Kafka đều xuất hiện trong danh sách giải pháp.
Điều đó khiến nhiều người đặt câu hỏi:
"Nếu đã có Redis thì có cần Kafka không?"
Hoặc:
"Nếu đã dùng Kafka thì Redis còn cần thiết không?"
Câu trả lời là:
Redis và Kafka không cạnh tranh trực tiếp với nhau. Chúng được tạo ra cho những mục tiêu hoàn toàn khác nhau.
Một cách đơn giản:
Redis dành cho tốc độ truy cập dữ liệu.
Kafka dành cho truyền tải và xử lý luồng sự kiện quy mô lớn.
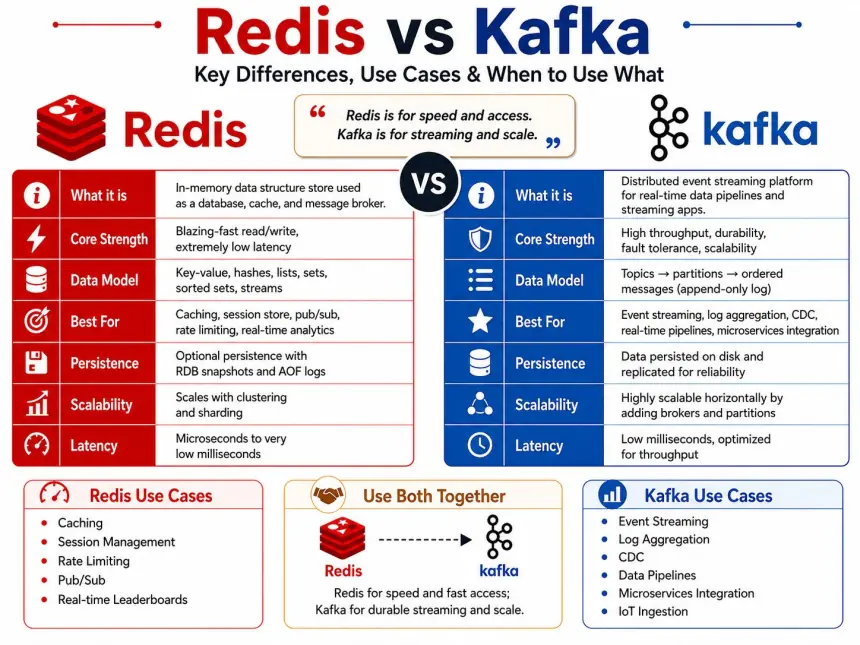
Redis là gì?
Redis là một hệ quản trị dữ liệu lưu trữ trên RAM.
Nó hoạt động như:
- Database
- Cache
- Message Broker
- Session Store
Dữ liệu được lưu trực tiếp trong bộ nhớ nên tốc độ truy xuất cực kỳ nhanh.
Thông thường thời gian phản hồi chỉ tính bằng:
- Microseconds
- Vài milliseconds
Đây là lý do Redis thường được sử dụng ở những nơi cần tốc độ cực cao.
Điểm mạnh lớn nhất của Redis
Theo hình minh họa:
Redis nổi bật ở:
- Blazing-fast Read/Write
- Extremely Low Latency
Điều này có nghĩa:
Redis không phải lựa chọn mạnh nhất về lưu trữ lâu dài.
Nhưng Redis gần như là lựa chọn hàng đầu khi cần truy cập dữ liệu siêu nhanh.
Ví dụ:
Nếu Database mất: 50 ms để truy xuất dữ liệu
Redis có thể chỉ mất: 0.2 ms cho cùng một dữ liệu.
Mô hình dữ liệu của Redis
Redis không chỉ lưu key-value đơn giản.
Nó hỗ trợ:
- String
- Hash
- List
- Set
- Sorted Set
- Stream
Điều này giúp Redis xử lý nhiều loại dữ liệu khác nhau mà không cần thiết kế quá phức tạp.
Redis phù hợp với những bài toán nào?
Caching
Đây là use case phổ biến nhất.
Redis được đặt giữa ứng dụng và Database.
Quy trình:
User → Redis → Database
Nếu dữ liệu đã tồn tại trong Redis:
Hệ thống trả về ngay lập tức.
Không cần truy vấn Database.
Session Management
Laravel, Django, Spring Boot và NodeJS đều thường sử dụng Redis để lưu Session.
Lợi ích:
- Hỗ trợ nhiều server
- Tăng tốc độ đăng nhập
- Không phụ thuộc file session local
Rate Limiting
Redis cực kỳ phù hợp để:
- Chống spam
- Chống brute force
- Giới hạn API
Ví dụ:
Mỗi IP chỉ được gọi API 100 lần/phút.
Pub/Sub
Redis hỗ trợ Publish/Subscribe.
Một service gửi message.
Nhiều service khác nhận được ngay lập tức.
Leaderboards
Nhờ Sorted Set.
Redis có thể:
- Xếp hạng game thủ
- Top doanh thu
- Top bài viết
- Top streamer
theo thời gian thực.
Kafka là gì?
Kafka là một nền tảng Event Streaming phân tán.
Nó được thiết kế để:
- Truyền dữ liệu thời gian thực
- Xử lý hàng triệu sự kiện
- Kết nối Microservices
- Xây dựng Data Pipeline
Khác với Redis.
Kafka không tập trung vào truy xuất dữ liệu siêu nhanh.
Kafka tập trung vào:
- Throughput cao
- Khả năng mở rộng
- Độ bền dữ liệu
Điểm mạnh lớn nhất của Kafka
Kafka nổi bật ở:
- High Throughput
- Durability
- Fault Tolerance
- Scalability
Kafka được thiết kế để xử lý hàng triệu sự kiện mỗi giây.
Ví dụ:
- Log hệ thống
- Giao dịch tài chính
- Dữ liệu IoT
- Clickstream
Mô hình dữ liệu của Kafka
Kafka sử dụng:
Topic → Partition → Ordered Messages
Mỗi message được ghi tuần tự vào log.
Đây gọi là:
Append-only Log
Dữ liệu không bị ghi đè.
Chỉ được thêm mới.
Điều này giúp Kafka:
- Đảm bảo tính thứ tự
- Dễ replay dữ liệu
- Dễ audit
Kafka phù hợp với những bài toán nào?
Event Streaming
Ví dụ:
Khách hàng đặt hàng.
Event: OrderCreated được phát ra.
Các hệ thống khác sẽ xử lý tiếp:
- Thanh toán
- Kho hàng
- CRM
Log Aggregation
Thu thập log từ:
- Web Server
- API
- Mobile App
- Microservices
về một nơi tập trung.
CDC (Change Data Capture)
Theo dõi thay đổi Database.
Ví dụ:
Khách hàng cập nhật thông tin.
Kafka phát hiện thay đổi và gửi tới các hệ thống liên quan.
Data Pipelines
Kafka là nền tảng của rất nhiều hệ thống Big Data.
Ví dụ:
Application → Kafka → Spark → Data Lake
Microservices Integration
Một service không cần gọi trực tiếp service khác.
Thay vào đó:
Service A → Kafka → Service B
Giúp giảm phụ thuộc giữa các hệ thống.
IoT Ingestion
Kafka rất mạnh khi nhận dữ liệu từ:
- Thiết bị IoT
- Cảm biến
- Camera
- GPS
với số lượng cực lớn.
So sánh Redis và Kafka
Tốc độ
Nếu xét về độ trễ (Latency):
Redis chiến thắng tuyệt đối.
Redis có thể phản hồi trong vài micro giây.
Kafka thường nằm ở mức vài mili giây.
Khả năng lưu trữ lâu dài
Kafka mạnh hơn.
Redis chủ yếu nằm trên RAM.
Kafka lưu trên ổ đĩa.
Có khả năng lưu trữ dữ liệu lâu dài.
Khả năng mở rộng
Cả hai đều hỗ trợ clustering.
Tuy nhiên:
Kafka được sinh ra cho scale ngang cực lớn.
Hệ thống có thể mở rộng bằng cách thêm:
- Brokers
- Partitions
Khả năng replay dữ liệu
Redis khá hạn chế.
Kafka lại rất mạnh.
Một consumer mới có thể đọc lại dữ liệu từ nhiều ngày hoặc nhiều tháng trước.
Đây là tính năng cực kỳ quan trọng trong Data Engineering.
Độ bền dữ liệu
Kafka được thiết kế để đảm bảo dữ liệu không mất.
Redis có Persistence:
- RDB
- AOF
Nhưng mục tiêu chính vẫn là tốc độ.
Khi nào nên dùng Redis?
Hãy chọn Redis nếu bạn cần:
- Cache
- Session Store
- Rate Limiting
- Pub/Sub
- Real-time Dashboard
- Leaderboards
- Temporary Data Storage
Nói cách khác:
Nếu bài toán là truy xuất dữ liệu cực nhanh.
Redis là lựa chọn hàng đầu.
Khi nào nên dùng Kafka?
Hãy chọn Kafka nếu bạn cần:
- Event Streaming
- Log Aggregation
- CDC
- Data Pipeline
- Microservices Communication
- IoT Data Collection
Nếu bài toán là truyền tải dữ liệu quy mô lớn.
Kafka là lựa chọn phù hợp hơn.
Trong thực tế, các hệ thống lớn thường dùng cả hai
Một sai lầm phổ biến là nghĩ rằng phải chọn Redis hoặc Kafka.
Thực tế:
Netflix
Uber
Airbnb
Spotify
đều sử dụng cả Redis và Kafka.
Một kiến trúc phổ biến:
User → API
API → Redis Cache
API → Kafka Event
Redis:
- Trả dữ liệu nhanh
Kafka:
- Xử lý sự kiện phía sau
Ví dụ:
Khách hàng tạo đơn hàng.
Redis:
Hiển thị đơn hàng ngay lập tức.
Kafka:
Gửi email
Cập nhật kho
Tính doanh thu
Đồng bộ CRM
một cách bất đồng bộ.
Đây là mô hình phổ biến nhất trong các hệ thống hiện đại.
Kết luận
Redis và Kafka không phải đối thủ của nhau. Chúng giải quyết hai nhóm bài toán hoàn toàn khác nhau.
Redis tập trung vào tốc độ truy cập dữ liệu với độ trễ cực thấp, phù hợp cho cache, session, rate limiting và các ứng dụng cần phản hồi tức thì.
Kafka tập trung vào luồng dữ liệu, độ bền và khả năng mở rộng, phù hợp cho event streaming, data pipelines và kiến trúc microservices quy mô lớn.
Nếu Redis là chiếc xe đua giúp dữ liệu đến người dùng nhanh nhất có thể, thì Kafka giống như một hệ thống đường cao tốc khổng lồ giúp vận chuyển dữ liệu an toàn, bền vững và có khả năng mở rộng gần như vô hạn.
Trong hầu hết các hệ thống hiện đại, câu trả lời không phải là Redis hay Kafka, mà là sử dụng Redis và Kafka cùng nhau để tận dụng thế mạnh của cả hai công nghệ.